
VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain
Paper Link
GitHub Code
Tabular Data is one of the most common types of data in the world and specifically in the tech industry. In addition, Semi-supervised and Self-supervised learning develops rapidly, being especially valuable in scenarios of limited-labeled and large-unlabeled data. Combining Deep Learning with SSL can be very powerful. So how can we combine the two?
Although Most of the Data out in the world comes as a Tabular data, funny enough the field of Deep learning methods for Tabular data is the least developed one (most of the focus is on Computer vision and Natural Language Processing).
The following paper tries to change that by working specifically on the Tabular data domain.
Machine learning for Tabular Data… let’s go!

Self-supervised learning also became a super effective technique to learn meaningful representations of the data, to be later used in various downstream tasks. It is widely common in Natural Language Processing (NLP).
There are several well-known works applying those techniques to computer vision and NLP, but tabular data wasn’t under the spotlight.
The following paper suggests a framework incorporating Self- and Semi-supervised learning, specifically for tabular data.
As a personal note and one that works with different kinds of data, indeed Deep learning for Tabular data is less common due to the fact that many times more classical and simple solutions work the same or even better.
So what the paper suggests?
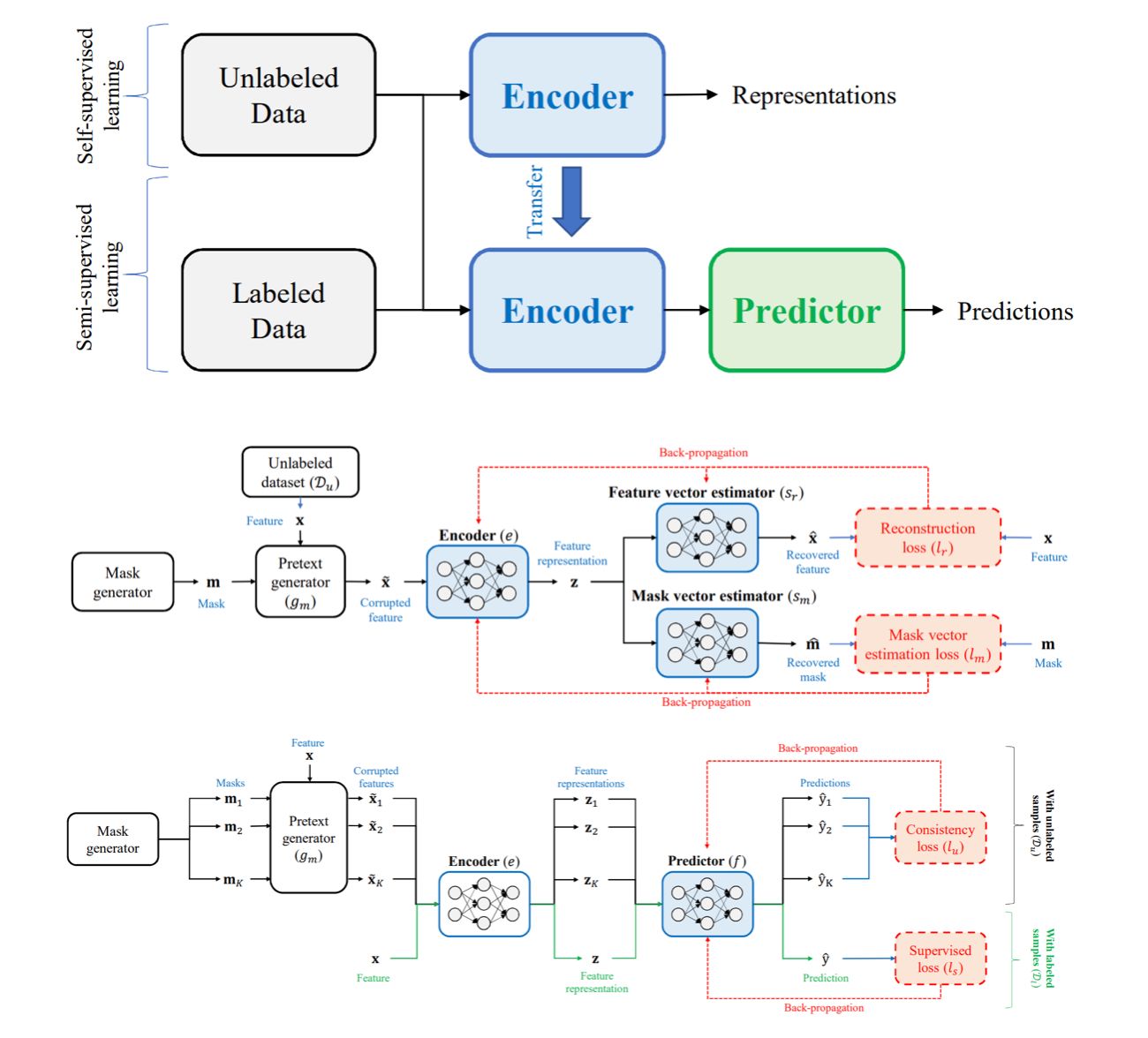
1. Incorporate both the labeled and unlabeled data.
2. Training an Encoder – using two sources of data with different Loss functions.
The training of the encoder holds two simple goals:
1. Encoder should be a good backbone network for the downstream Predictor network, thus one Loss term is associated with the underlying Classification/Regression task in place.
2. The latent representation which the Encoder learns for the labeled data, should be “close” to the embedding of the unlabeled data.
But what are the criteria for the Embedding learning part?
As with other techniques that sit under the same umbrella, the idea is to define an auxiliary task (which is not related to the downstream application), the auxiliary task should be hard such that it will enforce the network to learn meaningful features and connections in the Data.
Here, the paper suggests a Mask-and-Complete task in which data fields are masked in a random fashion, and the task is to predict unknown missing fields.
An important note is that this task does not use any labels, only uses the input. This paradigm is the basis of most of the Unsupervised techniques out there.
For All Papers Click here
For All Computer Vision Papers Click here
Take a look at the following article which also Suggests an SSL technique for Tabular Data – SCARP