
Learning a Weight Map for Weakly-Supervised Localization
Paper link
Explainable AI is one of the most important topics in AI and ML. I believe that down the line, in order to incorporate a Machine Learning model or algorithm we need to “trust” it.
In order to trust a Machine learning model we divided the discussion into two aspects:
1. The first is the most obvious one, trust is created by the performance of the model, measured by different metrics. Those metrics can be task-specific – such as Negative log-likelihood, or Accuracy in Classification tasks, or can be more of a Product specific like do the results are better than our alternatives, do the results make sense?
2. The second is the one we will cover a bit in this post, and is DOES THIS MODELS DECISIONS CAN BE EXPLAINED? I”m sure it is clear to anybody here that this is a crucial characteristic that we would like our model to support.
The are basically two families of models:
1. Classical and Simple models – Logistic regression, Decision Trees, Random Forest, Boosting algorithms, and so on. Those models most of the time are very explainable. We can understand what leads to the final prediction, the features’ importance, and many more.
2. Deep learning models – Neural networks, Transformers, Foundation models, and all the “exciting” models out there. The advantage with those models, mainly in Computer vision, Natural language processing, and Audio, is pretty clear – they are amazing at the tasks they are given to solve. But many times, it comes with the price of being more of a Black-box and a lack of interpretability.
That is why the field of Explainable AI (XAI) is super important for the advance and acceptance of State-of-the-art models.
The Paper
In the following post, we will dive into a Paper that tackles exactly the problem of Explainability. Specifically in the Computer vision field and Object localization task.
The paper set the focus on WSOL – Weakly supervised object localization.
🎯What is it you ask?
WSOL is the problem of localizing objects within images when only class labels are provided (no bounding box or segmentation). WSOL also can be looked at as “explainability” – without strong labels, WSOL outputs a Weight map that “explains” what is important (an object) in the image.
🎯So what this work suggests to do?
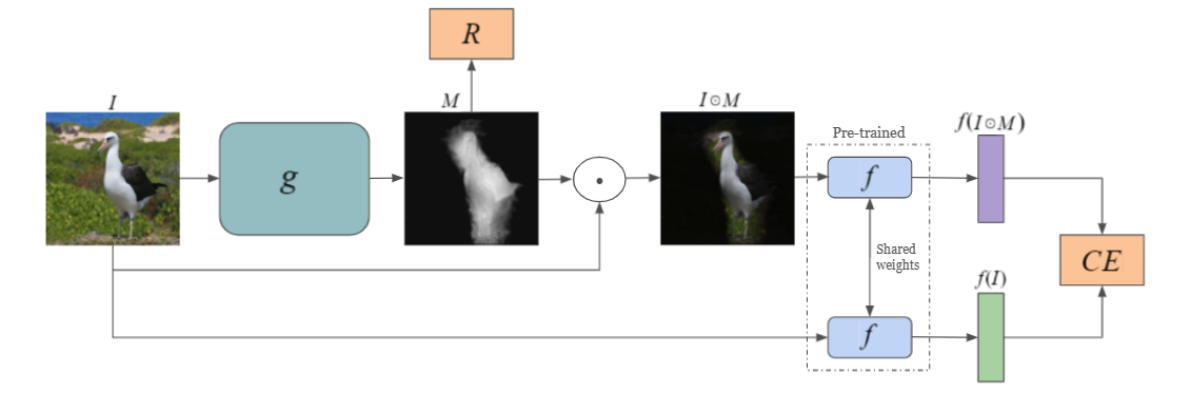
The paper suggests training a generator network conditioned on the input image, which outputs a Weight Map that corresponds to the localization of the object.
🎯 How to train the generator?
Training the generator is done via two methods –
1️⃣ The first is classifier-based with cross-entropy, such that generator weight map embedding will be close to the original image embedding.
![]()
2️⃣ The second, Siamese network with two triplet losses. The first triplet loss pulls the original image and its weight map (foreground) embeddings to be similar while pushing the original and background apart. The other triplet loss encourages the representation of masked (foreground) images of the same class to be similar while distancing the representation of foreground images from different classes.


Let’s see an illustration of this method and what exactly it does

If you reached here 😉 You may find the following interesting: