
Stochastic Restoration of Heavily Compressed Musical Audio Using Generative Adversarial Networks
Generative Adversarial Networks (GANs) to restore heavily compressed music files.
A paper from researchers at Sony Computer Science Laboratories (CSL), managed to incorporate a Deep Learning Generative Adversarial Network to restore (actually, stochastically generate) Music files after being heavily compressed.

GANs are all over the place, mainly in Computer vision application. They are being used to generate amazing high resolution images and even place you dog as if it went to space 😉
But what i love most is to see Machine learning and State-of-the-art techqniues such as GANs being used for Real life application and use cases.
What is the problem/task at hand?
We would like to compress our Audio files, there are many “deterministic” ways to do so as we all know. Those techniques have their limitation. What if GANs can do a better work. For example, identifying frequencies of the audio that are not really noticable by the human ear.
Here comes a Lossy audio codecs:
Lossy audio codecs compress (and decompress) digital audio streams by removing information that tends to be inaudible in human perception. Under high compression rates, such codecs may introduce a variety of impairments in the audio signal.
In such a scenario, there is no unique solution for restoring the original signal.
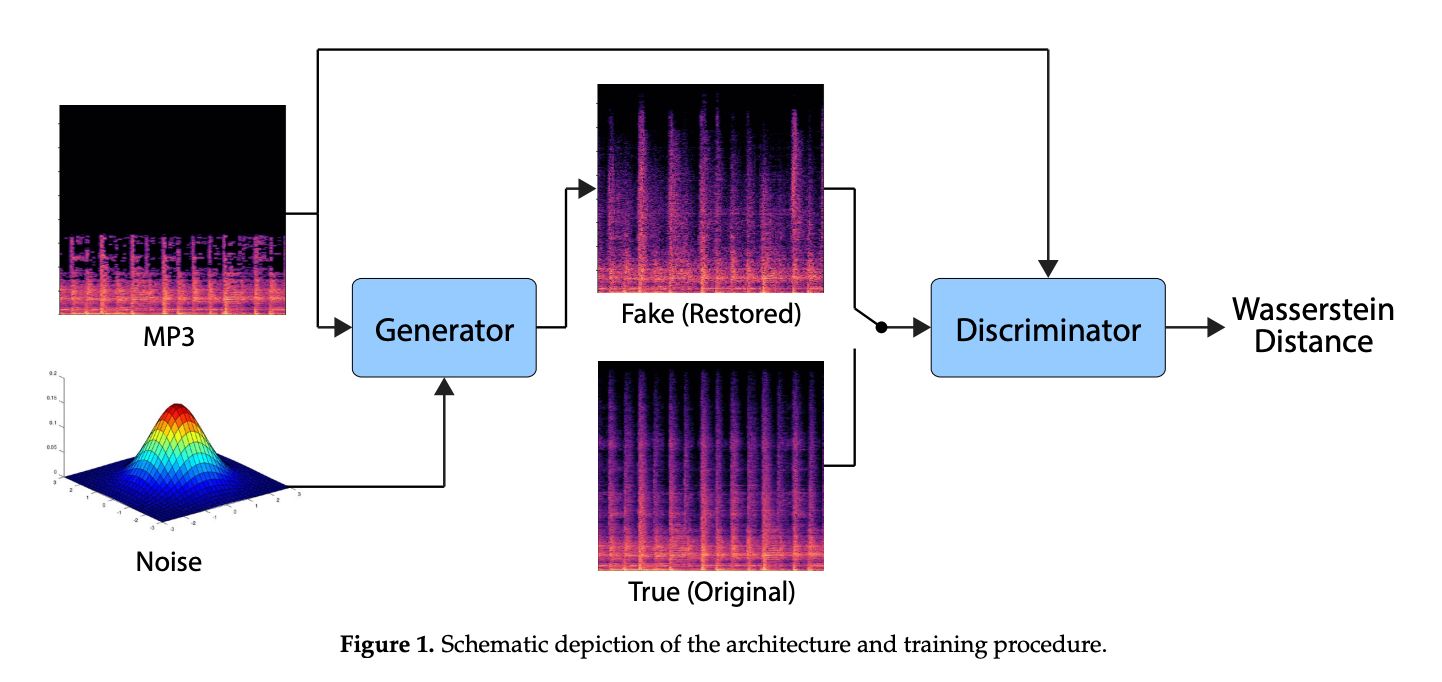
How the paper tries to solve the restoration problem? Using a relatively standard Conditional GAN architecture, the GAN is conditioned with the spectrogram of the compressed music file and outputs a decompressed version.
The Paper
What we condition on?
The spectrogram of the compressed music file is the signal that is fed into our GAN and serves as a condition.
The about the output?
The Generator outputs a decompressed version of the audio file.
#deeplearning #gans #papers #machinelearning #machinelearningalgorithms #restoration #music